
Decoding GA (not provided) is still a hot topic for SEOs.
Back in 2011 it was just a small problem for SEOs.
But now 99%+ of Google Analytics keywords are not visible.
This used to to be a treasure trove of useful information about visitor behavior and keyword conversions.
However, gradually since 2011, when Google released the Secure Search update, almost all organic searches are hidden as (not provided).
And the ratio of Google Analytics keywords not provided surged from about 41% to over 80%.
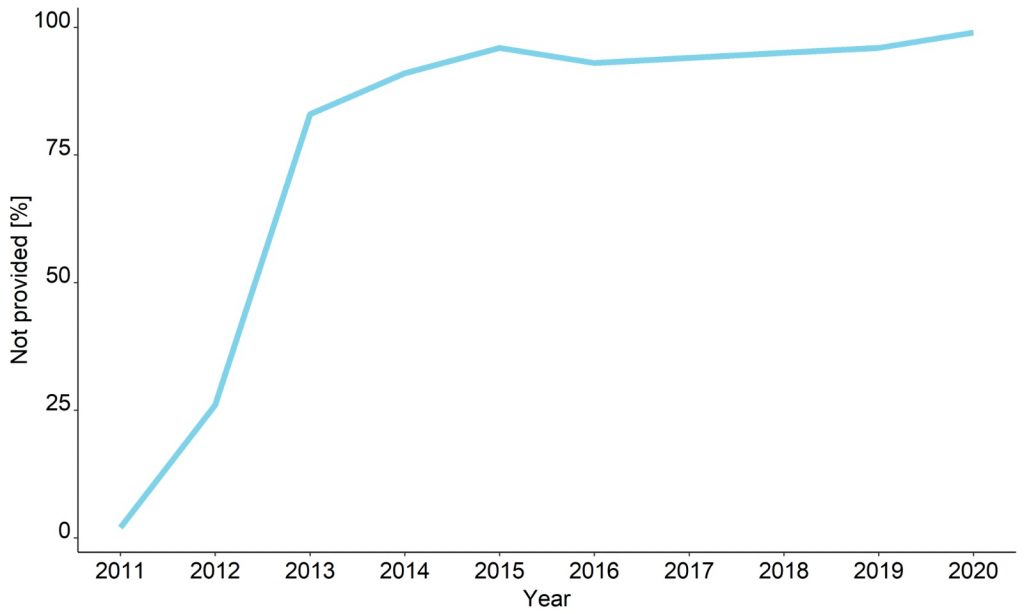
Now it is over 99%.
Is this an attempt by Google to persuade more users to pay for keywords visibility through Google Ads?
It could be. But, knowing Google’s motivation is not as important as figuring out how to get these keywords back.
In this article, I will explain in detail how we use advanced data processing to reverse engineer your keywords back.
7 steps to decode GA (not provided)
- Step 1: Pull together nine different data sources
- Step 2: Perform data analysis
- Step 3: Analyze organic traffic for keyword fluctuation in Google Serp
- Step 4: Train the keyword classifications
- Step 5: Match sessions with keywords using an algorithm
- Step 6: Start computation to unlock keywords not provided
- Step 7: Session vs. string-based matching
You can see in the below image that not provided organic search accounts for almost all of the below organic traffic.
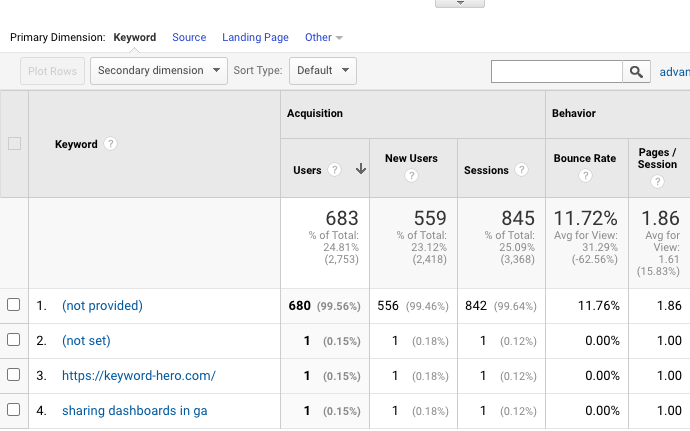
Let’s take a look at GA (not provided) and how you can unlock this.
But first, let’s start with how (not provided) became an issue in the first place.
A brief history of (not provided)
To get a complete picture of why this matters so much, we need to jump into our time machine and take a trip back to 2011.
Google Analytics had just launched, and website owners were bestowed with access to a vast well of information.
In the organic search report, you could see which keywords brought visitors to your site.
And how user behavior changed with different keywords.
This made it easy to see which keywords were the most valuable.
Let’s take an example.
Say an ecommerce retailer observed that people who arrived on his site after a long-tail keyword search like ‘Adidas high top trainers’ had a high conversion rate.
He could optimize that page to closer match user intent.
But in 2011, that all changed when Google started encrypting search data.
According to Google, this move was made to protect users’ privacy.
As co-founders Larry Page and Sergey Brin disclosed, the increased privacy measures were taken partly due to the introduction of personalized search results.
Nowadays, most of us don’t even consider the fact that our search results take personal information into account.
Like when you search for restaurants in New York and expect Google to show you restaurants close to your current location, even if you didn’t search for ‘Italian restaurants in New York’ for instance.
But this wasn’t always the case.
As Google started incorporating personal information into search results, they had to protect users’ personal information.
They achieved this by encrypting keywords from logged-in Google users.
So, how does that process work?
Before this change, a normal Google search would redirect users to an HTTP version of the domain they clicked on.
This might seem like a small change, but it had a huge impact on our ability to access keywords.
That’s because redirecting users to a secure version of their desired domain encrypts their search queries.
GA (not provided) encrypted
For privacy concerns, this change was fantastic.
And I’m glad for it.
The new encryption process added an extra layer of security to Google search.
However, it became a huge obstacle for SEO and the online marketing world.
When this change came into effect, SEO professionals suddenly lost a large chunk of information.
The quest to unlock GA (not provided) has been the dragon in the cave for SEO.
There is good news though, there is a way to reveal all organic keywords including all session metrics.
Keyword Hero can retrieve between 85-95% of all keywords in seven steps.
7 Steps to get your organic keywords back
Step 1: Nine different data sources used
A crucial first step is to use keyword data from 3rd party sources ( browser extensions, and rank monitoring services).
Along with first party data from Google Analytics and Search Console data.
Next massive parallel, cloud-based artificial intelligence / machine learning algorithms statistically match search phrases to sessions and cluster them.
This data is then uploaded back to a new Google Analytics property (so all of your familiar metrics are visible).
This allows you to analyze your new data set in a familiar setting without interfering with your original data.
Step 2: Perform data analysis
Once a user signs up, the Hero analyzes Google Analytics account history, looking for:
- Patterns e.g. site structure, Urls that pull traffic; clusters among organic traffic; device categories; time / date; locations
- Type and content e.g. number of direct sessions attributed to organic; news or ecomm; one-pager or many product sites; semantical topics
The software then generates a large set of possible keywords per Url using:
- 3rd party data sources e.g. rank monitoring services, browser extensions data, Bing search API
- 1st party user data including Google Search Console and the remaining keywords in GA
The result is one big bucket with all possible keywords per Url.
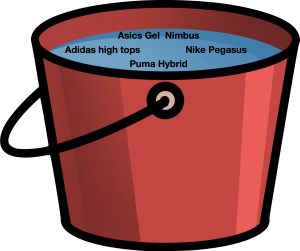
None of this would be particularly useful unless the data is clustered and classified.
Using external APIs we look for abnormal behavior in a keyword’s history.
Were there changes in traffic in the last 12 months (per country / device)?
Is this a new keyword? Did spikes occur? Is there a reference article on Wikipedia if so how does it behave?
After the hero creates a keyword set and checks for potential spikes and abnormalities, he tries to understand the keyword.
Is this a brand keyword or a non-brand keyword?
Is it a person / brand name? (important for n-gram analysis).
Is the keyword transactional / navigational or
informational?
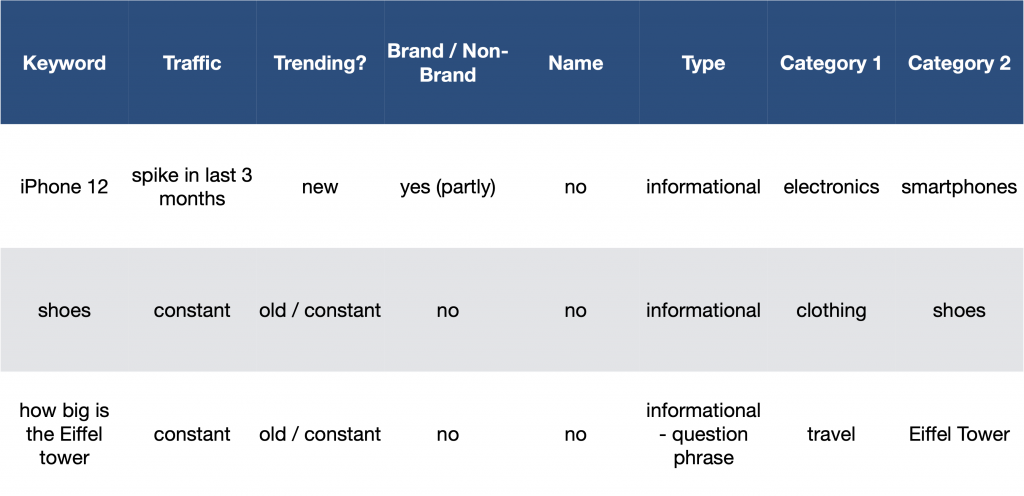
The result is one big data frame where certain parameters are attributed to the keywords.
Step 3: Analyze organic traffic for keyword fluctuation in the Serp
Let’s suppose we have a site that ranked on positions 13 – 15 in calendar week X for the term “shoes”.
At this point we have the following metrics for this landing page:

In calendar week X + 1 the site now ranks position 5 for shoes and the metrics changed to:

In this simple example we assume ceteris paribus, that nothing else has changed.
Almost all new sessions can be attributed to “shoes”.
Why is this keyword analysis important?
With just a few computations we gain some valuable insights.
1. “Shoes” in position 5 brings in 1000 more daily sessions compared to position 13 – 15
2. The bounce rate of the keyword is identical to other keywords that rank for this site
3. The conversion rate of this keyword seems to be significantly lower than the conversion rate of the others
It has brought only 5 more conversions with 1000 sessions, compared to the 10 conversions with the 500 sessions we had before.
When analyzing this, we take a couple of factors into consideration, most importantly:
- Seasonal fluctuations
- Overall site performance during this time frame
- Keyword performance → is the spike due to a trend?
Luckily the search engine results page changes quite a lot, otherwise, this would not be possible.
Step 4: Train the keyword classifications
At this point, we need to start matching keywords and sessions.
Using the previously generated data, the Hero tries to calculate the probability of a certain keyword matching a cluster of sessions.
Sessions that were captured through extensions and those where the keyword is still visibly in Google Analytics (= “hard data”) can be matched with 100% certainty, so these will be left out.
After the first probability is calculated, the data will again be compared against the “hard data”.
This happens on the cluster level to adjust the classifications.
After the first iteration, the Hero constructs strings from the GA data.
These strings contain between 5 and 25 dimensions.
It’s interesting how few sessions are left if you query a big string.
You can check this for yourself using the Core Reporting API, where you get up to 7 dimensions in one string.
Now, the keywords have been clustered sufficiently and you get only a handful of sessions back from one string.
This leaves very few potential keywords per cluster of session (the cluster has gotten smaller, too).
Still with me?
An unfair visual representation
Keyword A
Keyword A might now be matched with one or more of those sessions.
This is a session cluster, containing four sessions.
This results from the Hero requesting all sessions with a certain string.
Step 5: Match sessions with keywords using an algorithm

At this stage, we create an adjusted, unique algorithm for your account, that tries to match sessions with keywords.
He then applies this algorithm to the entire history of the GA account.
And then matches the results with the “hard data”.
Which are the remaining visible keywords and the keywords captured by browser extensions.
After this last step, the algorithm is ready to go for each page.
In most cases, the historic data is not enough.
Because some data sources are not available retrospectively, which is why the Hero works better after a month.
Step 6: Start computation to unlock keywords not provided
After all that learning, the Hero can finally start.
The computational process is essentially the same as the training process:
1. Compute possible keywords
2. Check results against “hard data”
3. Adjust classifications based on results
Now we have the final output unlock GA (not provided).
The matching does not happen through CIDs.
Looking at that mirrored account, you’ll see that some dimensions are missing.
This is because the matching happens based on dimension strings and not sessions.
Are you still reading?
Good, because this is where it gets interesting.
Step 7: Session vs. string-based matching
If the data was session-based, you’d get everything back like this:

But what it looks like instead is this:
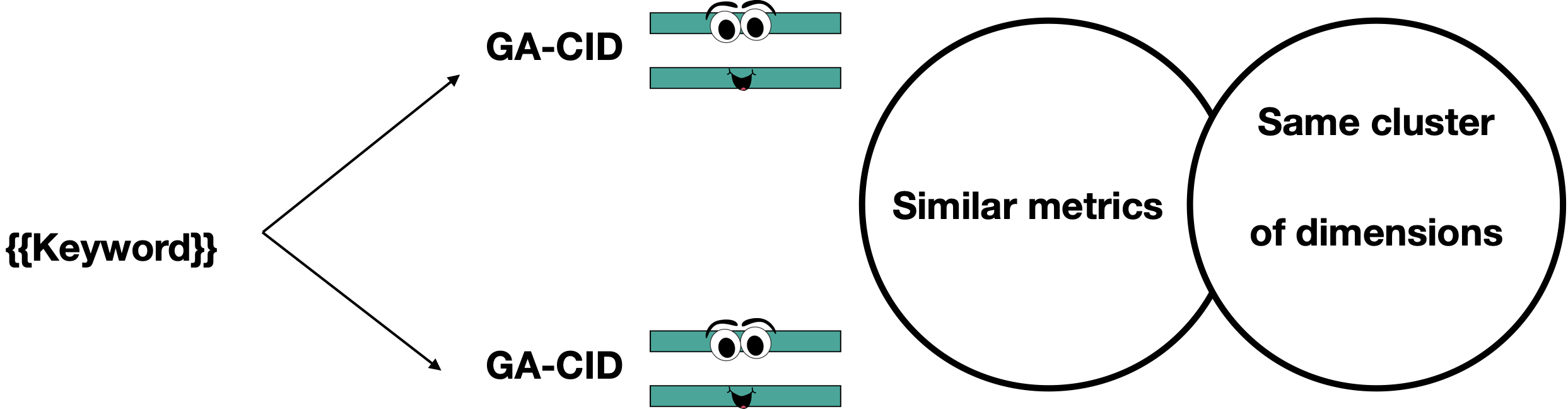
But why only 83% certainty?
You may have seen this number on our website.
This is just the average threshold we use because it’s easier to communicate.
In reality, the certainty threshold for a keyword to match with a session varies between 80% and 85%.
The certainty level is based on the assumption that 95% of all possible keywords not provided have been found in the first bucket (see the big red keyword bucket above.)
And there you have it GA (not provided) decoded.
Test it for 90 days risk-free.
